

为了高效的保存p站上的插画,于是便想着自己写个python爬虫,通过插画id或者画师id来检索下载插画,并重新规范一下爬下的插画名字,便于整理(@画师名 插画id.图片格式)
以下是我的爬取过程,可能也存在一些纰漏,也请大佬多多批评指正🤗
完整代码已上传github:
以下是我早期的一些思路:
目前需要用到的python库
import re # 用正则提取文本
import time # 设置等待时间
import requests # 发送各种网络请求
import urllib3 # urllib3.disable_warnings() 避免 SSL/TLS 连接时因证书验证问题而输出的警告
import json # 解析json
import random # 随机数生成
from bs4 import BeautifulSoup # 从HTML标签中提取数据
import os # 构建文件夹保存插画
import multiprocessing # 多进程下载模拟登录
放个登录链接:https://accounts.pixiv.net/login
首先我们得解决登录的问题。不登录也没事,那你可能爬不到插画或者数量不全😋
目前我所知道的三种爬虫登录方法:
POST 请求方法:需要提前获取登录时的 URL并填写请求体参数,然后进行 POST 请求登录,相对麻烦;
添加 Cookies 方法:先登录,再将获取到的 Cookies 加入 Headers 中,最后用 GET 方法请求登录,这种最方便;
Selenium 模拟登录:代替手工操作,自动完成账号和密码的输入,只要能找到对应的标签就能实现但速度比较慢。
本人试过前两种方法。至于第三种,因为不想导入那么多的包,而且也麻烦,就不用了。
对于第一种,之前也参考过很多教程,大部分都说参数是提交账号,密码,return_to,还有一个post_key,但是我发现,截止2024年,这种方法已经不管用了,pixiv的登录方式更新了。
现在又多了个recaptch,post_key也变成了tt,而且这两个数据是会变的。
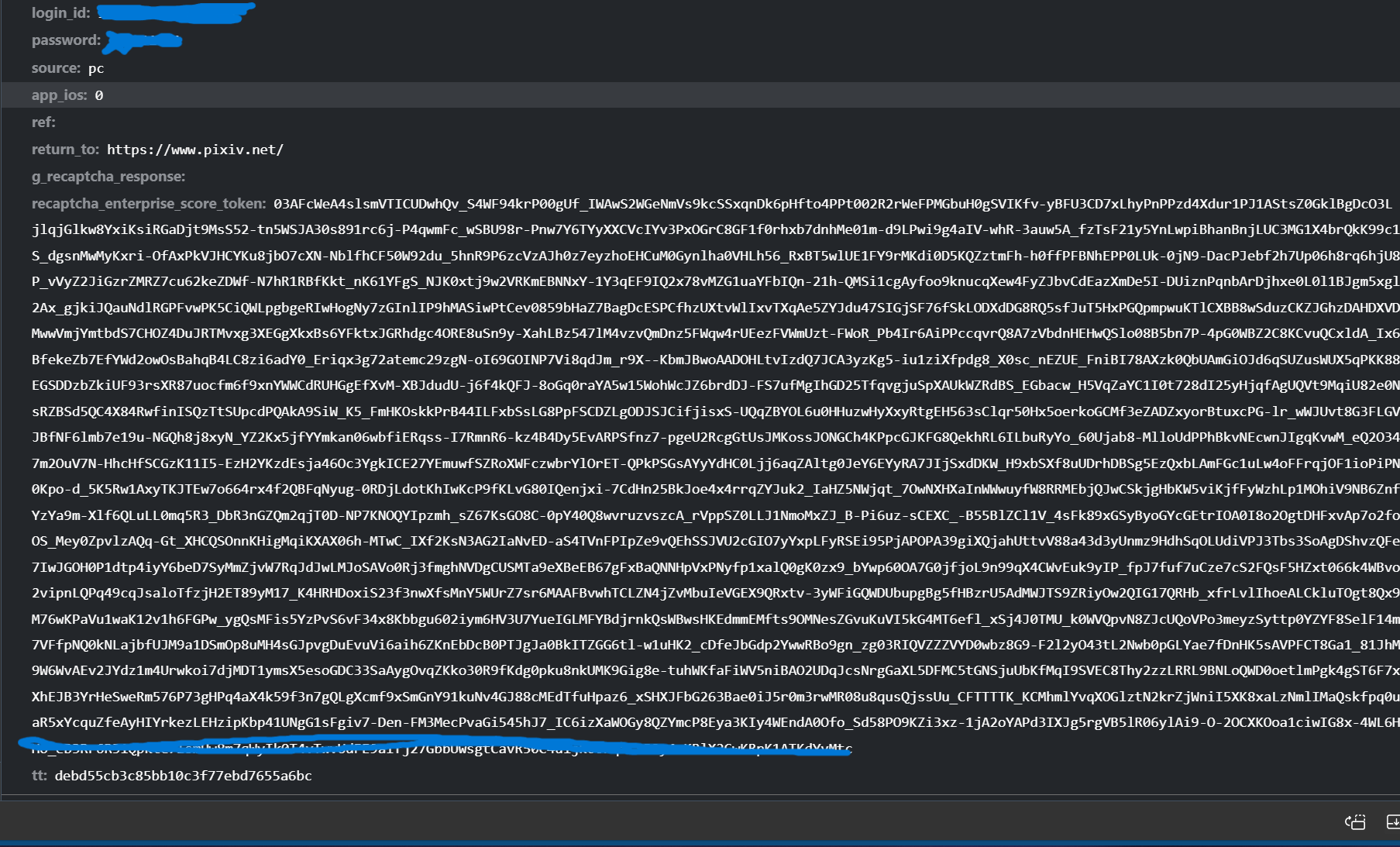
tt想获得非常简单在登陆页面的html里就能找到,但是recaptcha的token我一直找不到方法获得。

所以最后我还是换成第二种方法,登录之后随便找一个访问到pixiv的请求,复制里面的cookies到请求头中。
headers = {
'referer': "https://www.pixiv.net/", # 携带referer是因为p站的插画链接都是防盗链
"user-agent": '', # 自行填入请求头信息
"cookie": '' # 自行去获取cookies
}绕过登录后,我们就可以继续进行了。
开始爬取
单图检索
目前已知的p站插画的访问路径是:https://www.pixiv.net/artworks/插画id
但是我发现获得html后是找不到原始插画的链接,而且多张插画也不会显示出来。
最后摸索了一下,才发现p站是有API可以调用的:https://www.pixiv.net/ajax/illust/插画id/pages?lang=zh
例如访问
可见插画是以ajax请求并返回一个json数据:
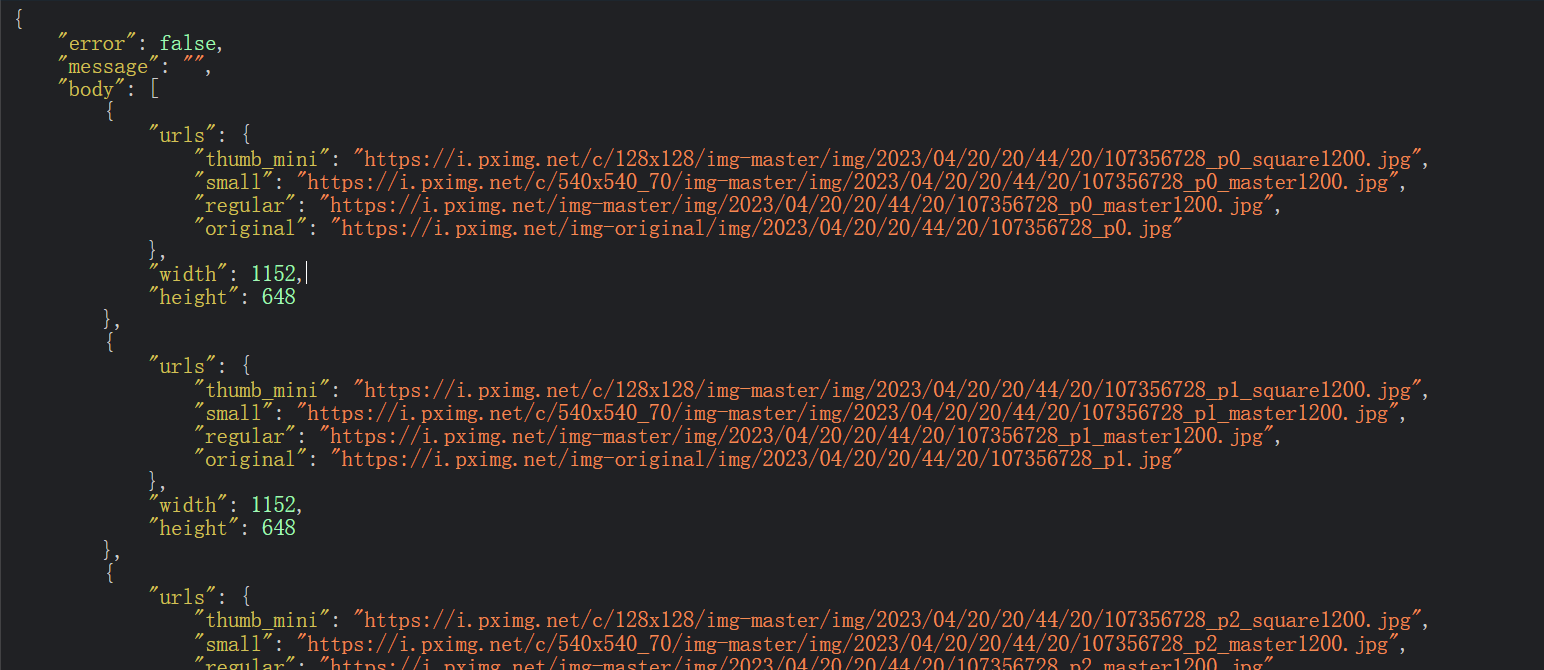
我们要找的插画数据就在“body”的“urls”里,一般同个id里,插画有多少张这里列表就有多少数据,“original”就是插画的直链。
直接访问链接的话会显示403,
因为pixiv限制了必须从pixiv网页点进这个网址,所以必须得headers构建referer才能访问。
def downLoad():
"""
下载插画。
通过发送HTTP请求获取插画的页面信息,并下载这些插画。
首先创建一个requests会话,然后发送GET请求以获取插画页面的JSON数据。
如果请求成功,将解析JSON响应以获取插画的URL,并将这些插画下载到本地目录中。
"""
try:
session = requests.Session()
# 发送GET请求以获取插画页面的数据
response = session.get(url=f"https://www.pixiv.net/ajax/illust/{img_id}/pages?lang=zh",
verify=False, headers=headers)
if response.status_code != 200:
print(f"请求失败,状态码: {response.status_code}\n")
return
# 解析响应以获取插画的URL
url = json.loads(response.text)['body']
if len(url) == 0:
print("未找到该插画~\n")
return
except json.decoder.JSONDecodeError:
print("你的cookie信息已过期\n")
else:
# 这里我创建一个目录以存储下载的插画
mkdirs = os.path.join(os.getcwd(), "artworks_IMG")
if not os.path.exists(mkdirs):
os.mkdir(mkdirs)
# 遍历id里所有插画的URL并下载
for ID in url:
href1 = ID['urls']['original']
download_response = session.get(url=href1, headers=headers, verify=False)
if download_response.status_code != 200:
print(f"下载失败,状态码: {download_response.status_code}\n")
else:
# 构建文件路径并保存插画
file_path = os.path.join(mkdirs, f"@{getWorkerName()} {os.path.basename(href1)}")
with open(file_path, "wb") as f:
f.write(download_response.content)
为了整理文件,所以我还需要获得画师的名字,这个不难,在插画的访问地址请求的html中就能找到:
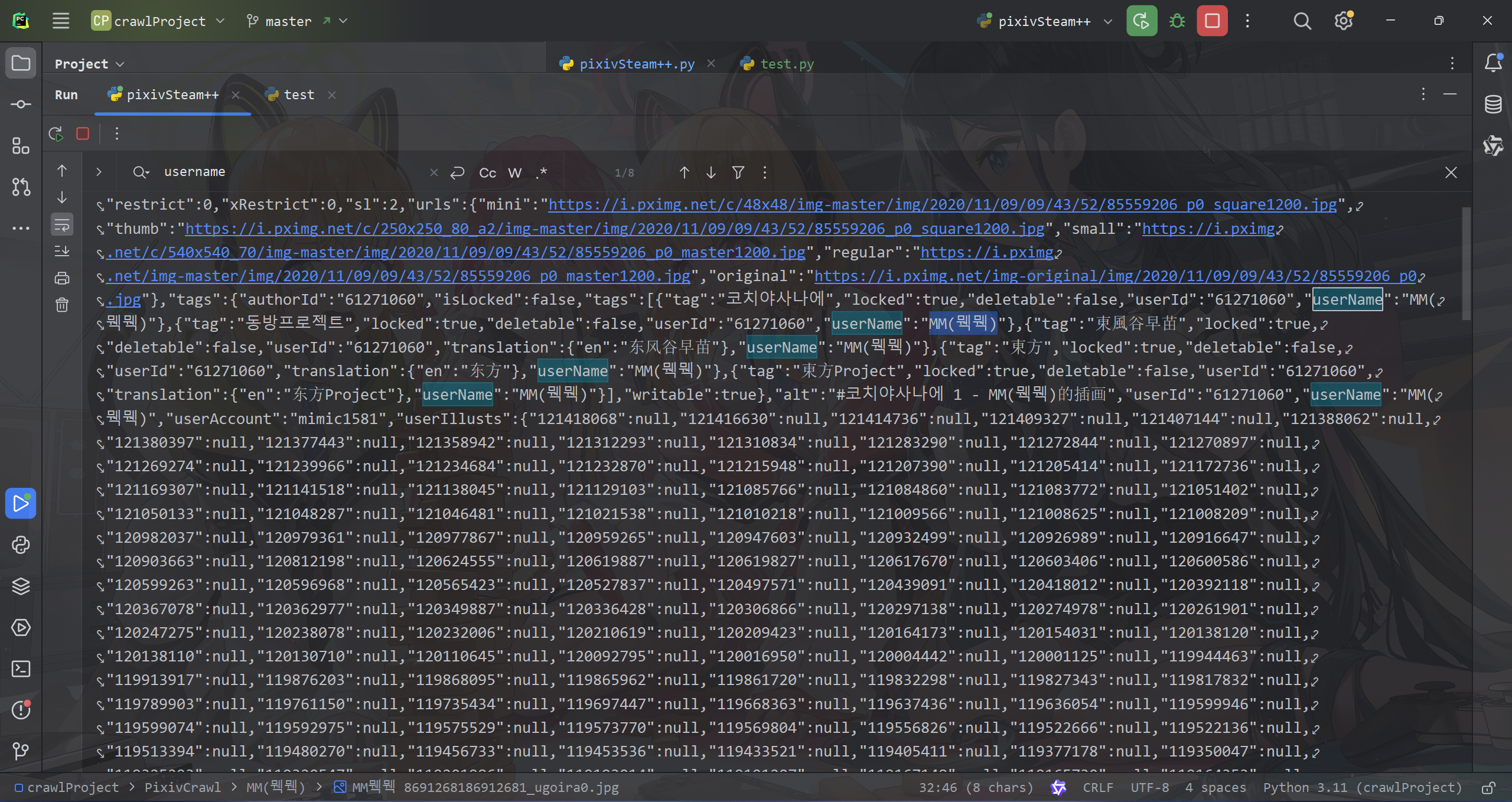
def getWorkerName():
"""
获取画师的名字
通过访问Pixiv网站,使用BeautifulSoup和正则表达式提取画师名字
返回值为画师名字
"""
artworks_id = f"https://www.pixiv.net/artworks/{img_id}"
requests_worker = requests.get(artworks_id, verify=False, headers=headers)
requests_worker.raise_for_status()
# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(requests_worker.text, 'html.parser')
# 获取页面中所有的meta标签,并转换为字符串
meta_tag = str(soup.find_all('meta')[-1])
# 尝试从meta标签中提取画师名字
try:
username = re.findall(f'"userName":"(.*?)"', meta_tag)[0]
username = re.sub(r'[/\\| ]', '_', username)
except IndexError:
print("未找到该作品的画师~\n")
else:
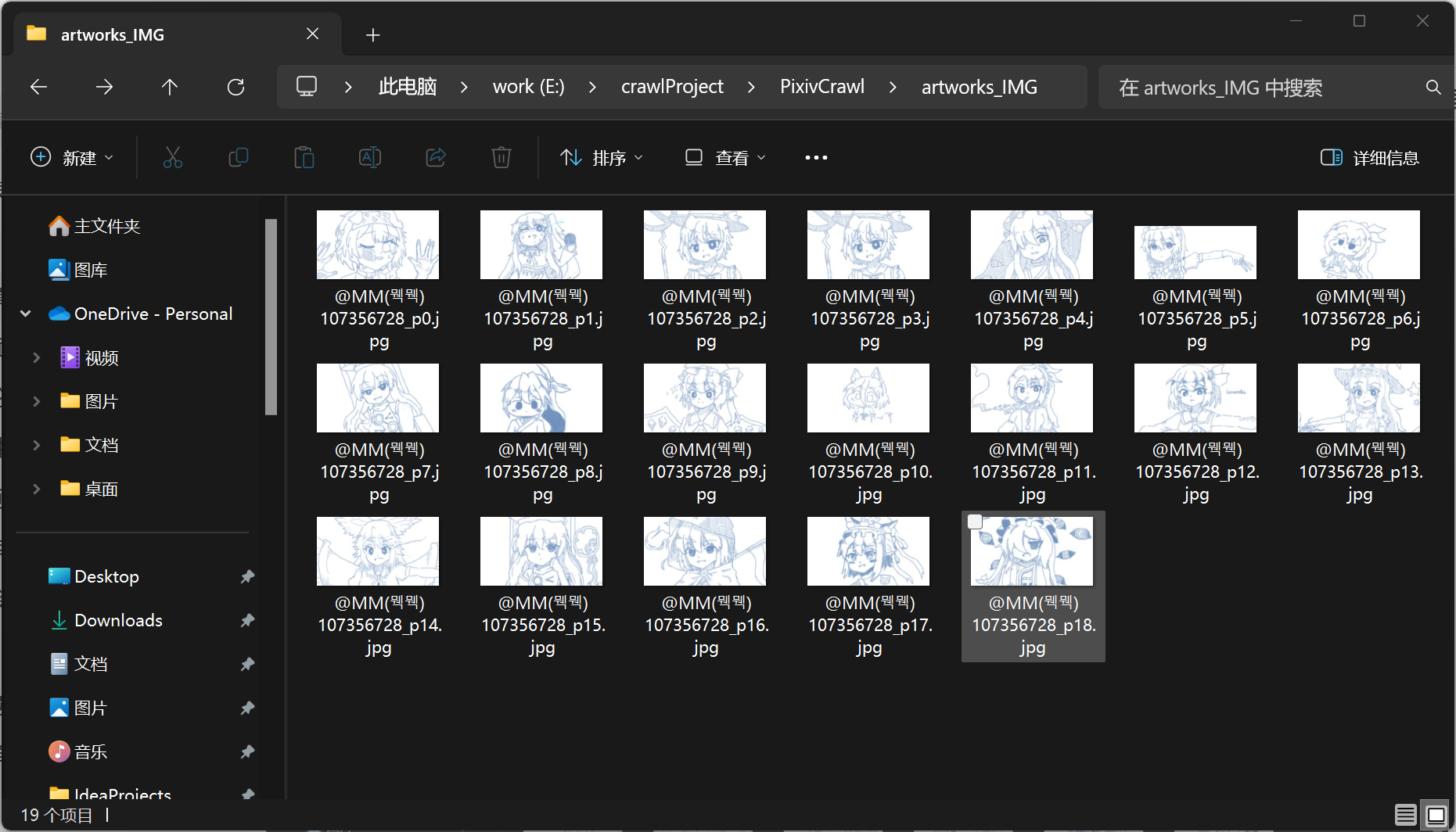
return username这样就能根据插画id爬取插画了:
画师检索
知道了怎么单图爬取,那么多图爬取就不难了。
主要思路就是通过画师id来获取他的所有作品id,然后遍历下载。
画师主页的访问地址一般是:https://www.pixiv.net/users/画师id
既然图片有api,我猜画师应该也会有,
不出所料,被我言中了:https://www.pixiv.net/ajax/user/插画id/profile/all?lang=zh
例如访问
可以看到图片id全放在“illusts”里,所以作品id也很好获得了。
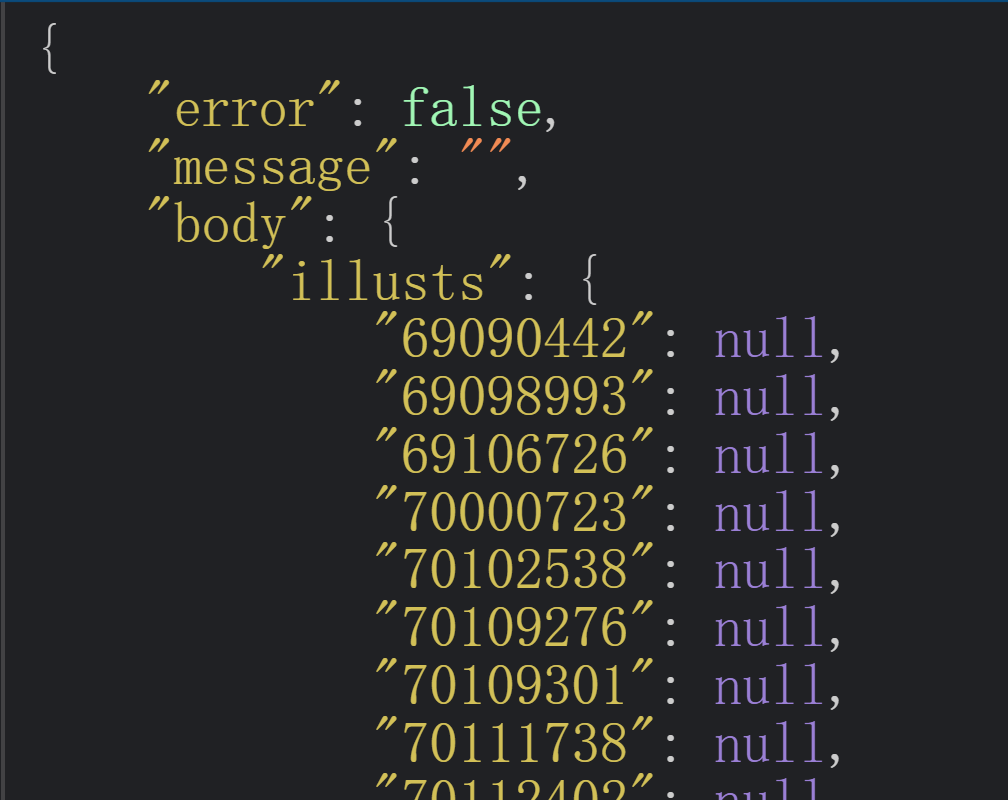
def getImgId():
id_url = f"https://www.pixiv.net/ajax/user/{users_id}/profile/all?lang=zh"
try:
response = requests.get(id_url, headers=headers, verify=False)
response.raise_for_status()
# 利用正则表达式提取作品ID
artworks = re.findall(r'"(\d+)":null', response.text)
except requests.RequestException as e:
print(f"网络请求错误: {e}")
artworks = []
# 返回提取到的作品ID列表
return artworks接下来就可以下载了,这里我用到了多进程。
def download():
"""
下载图片资源。首先获取图片ID列表,并创建存储图片的文件夹。
使用多进程下载图片,并打印下载耗时和文件夹内图片总数。
"""
try:
# 获取图片ID列表
listId = getImgId()
print("所有作品ID如下:")
print(listId)
print(f"大概下载图片数: {len(listId)}+")
# 创建以作者名命名的文件夹
mkdirs = os.path.join(os.getcwd(), getWorkerName())
os.makedirs(mkdirs, exist_ok=True)
# 开始下载
time_start = time.time()
print("正在检索并下载中,请稍后。。。")
# 使用多进程来下载图片,进程数取决于你的cpu性能
num_processes = multiprocessing.cpu_count()
with multiprocessing.Pool(processes=num_processes) as pool:
pool.map(down, listId)
# 完成下载
time_end = time.time()
time_sum = time_end - time_start
print(f"下载完成,共耗时{time_sum:.2f}秒~ 文件夹内共有{len(os.listdir(mkdirs))}张图片~")
except TypeError:
print("输入的画师id有误或不存在,也可能是你cookie失效了,换一个吧~\n")
except Exception as e:
print(f"发生了一个错误: {e}\n")
def down(ids):
"""
:param ids: pixiv插画的ID。
"""
# 随机等待时间,防止因频繁请求而被网站限制
second = random.randint(1, 4)
mkdirs = os.path.join(os.getcwd(), getWorkerName())
illust_url = f"https://www.pixiv.net/ajax/illust/{ids}/pages?lang=zh"
try:
# 发送HTTP请求获取插画信息
res_json = requests.get(url=illust_url, headers=headers, verify=False).text
except requests.RequestException as e:
print(f"请求失败: {e}")
return
# 解析JSON响应,提取图片URL列表
try:
url_list = json.loads(res_json)['body']
except (json.JSONDecodeError, KeyError) as e:
print(f"解析JSON失败: {e}")
return
# 遍历图片URL列表
for ID in url_list:
href1 = ID['urls']['original']
# 发送请求获取图片内容
try:
response = requests.get(url=href1, headers=headers, verify=False)
response.raise_for_status()
except requests.RequestException as e:
print(f"下载失败: {e}")
continue
filename = f"@{getWorkerName()} {os.path.basename(href1)}"
# 构建图片的文件路径
filepath = os.path.join(mkdirs, filename)
# 下载
if not os.path.exists(filepath):
with open(filepath, "wb") as f:
f.write(response.content)
time.sleep(second)
获取画师名字的方法和单图那里写的差不多,这里不在赘述了,留给读者自己思考。
至此,就能通过画师id下载ta的作品了🥰
补充——动图下载
偶然的,我发现pixiv原来是有动图的,但仅仅通过上述的方法只能下载到静态图片。在网页上搜索直接下载,也是不能存为gif格式。
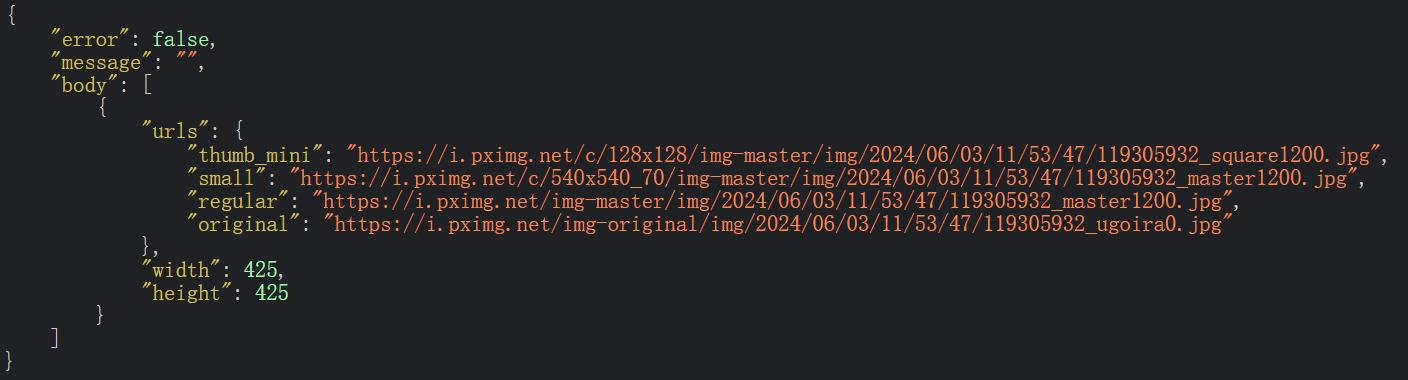
咱们以这张图为例吧(id:119305932):

访问之前单图检索的API,并不能发现gif:
在网上找了一下相关资料,发现p站的动图不是以gif格式保存,而是多帧图片拼在一起形成的动态效果,存在ugoira里面。保存数据的API具体地址:https://www.pixiv.net/ajax/illust/插画ID/ugoira_meta
例如访问
可以看到数据是放在zip里面的:
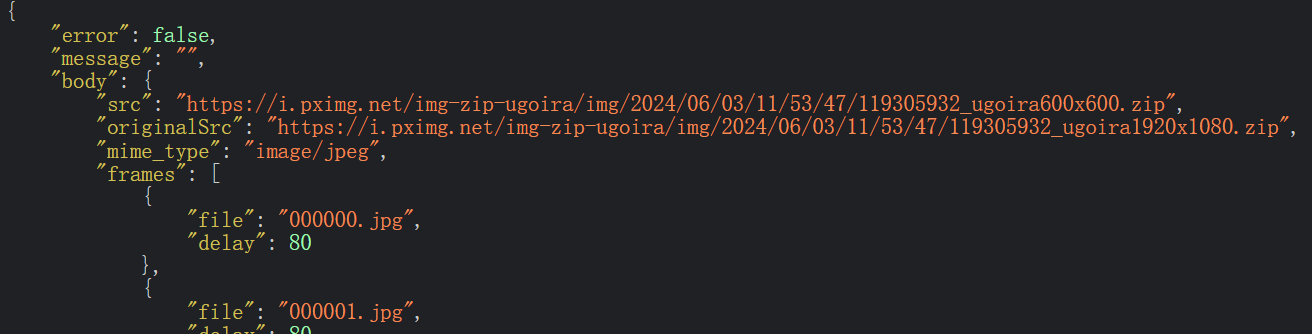
原图链接就放在“originalSrc”里面,图片以及帧延迟时间放在“frames”里面。
这就好办了,只要获取到zip里面的图片在拼成gif就好了。
一些情况
是动图时,访问https://www.pixiv.net/ajax/illust/插画ID/ugoira_meta,结果如上图所示。
不是动图,则返回:
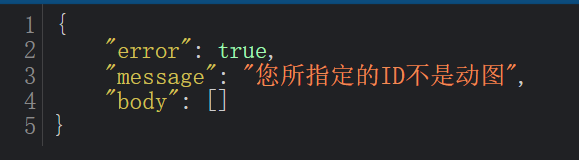
如果插画本身不存在:
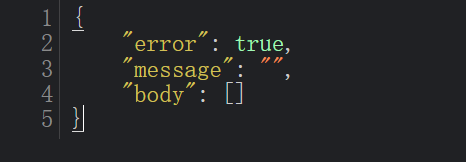
可以"error"为false时,该插画就是动图了。
要用到的库
import io # 用于处理I/O操作,这里主要用于内存文件操作
from PIL import Image # 用于处理图像文件,合成gif
import requests # 发送各种网络请求
import urllib3 # urllib3.disable_warnings() 避免 SSL/TLS 连接时因证书验证问题而输出的警告
import zipfile # 用于处理zip压缩文件先通过zipfile模块解压一下获取的zip文件,可以看到:
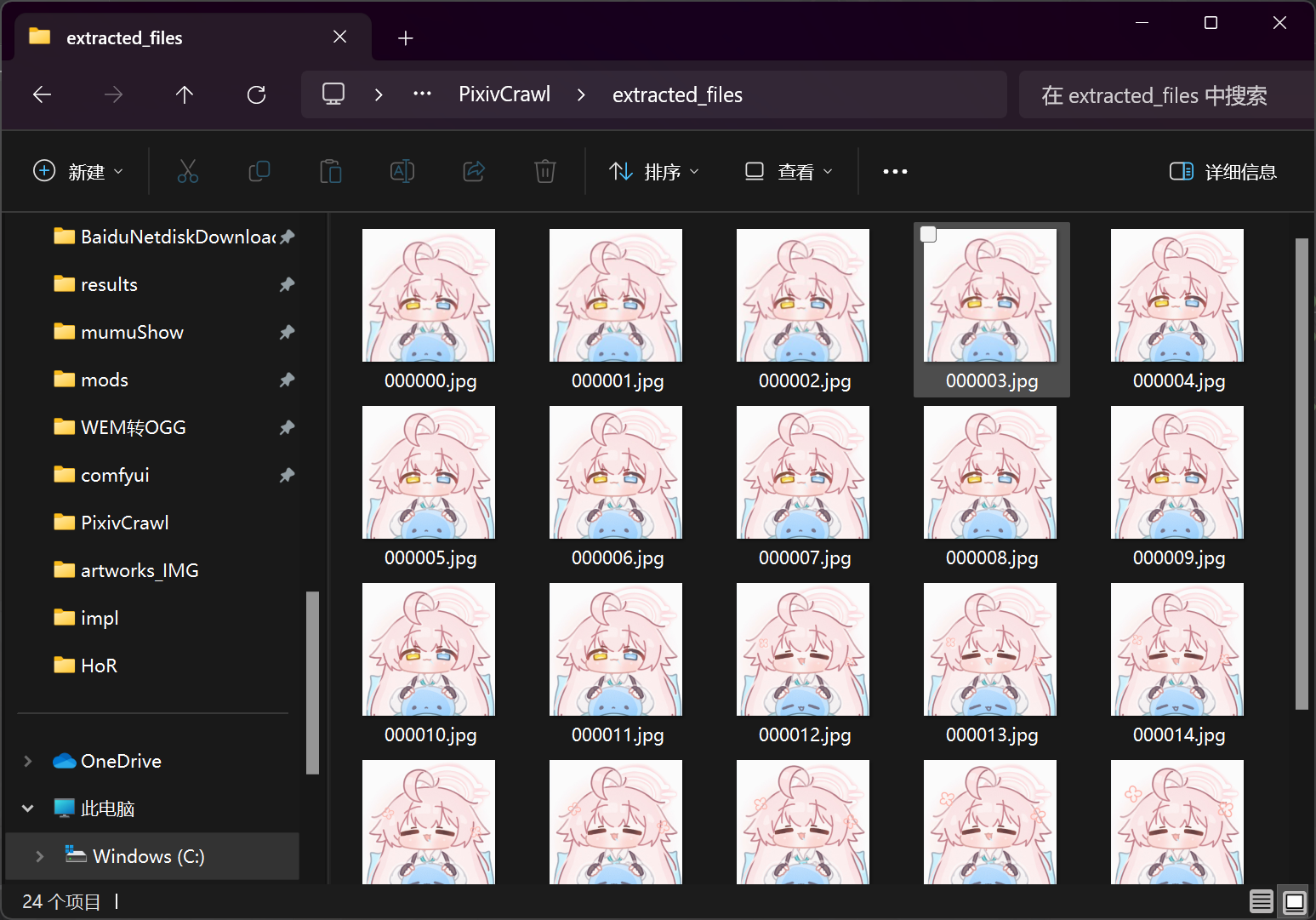
p站上的图片确实是由多张图片合成的。
# 解压ZIP文件
with zipfile.ZipFile("download.zip", 'r') as zip_ref:
zip_ref.extractall("extracted_files")代码部分
我也不多废话了,直接放示例代码吧:
def download_and_convert_ugoira(illust_id):
"""
下载并转换Pixiv动图(Ugoira)为GIF文件。
参数:
- illust_id (int): Pixiv插画ID
"""
# 定义请求的URL
url = f"https://www.pixiv.net/ajax/illust/{illust_id}/ugoira_meta"
# 定义请求头,包含referer、user-agent和cookie等信息
headers = {
'referer': "https://www.pixiv.net/", # 携带referer是因为p站的插画链接都是防盗链
"user-agent": '', # 自行填入请求头信息
"cookie": '' # 自行去获取cookies
}
# 发送GET请求获取动图元数据
response = requests.get(url, verify=False, headers=headers)
# 将响应内容解析为JSON格式
data = response.json()
if data['error']:
print("这不是动图~")
return
# 获取原图URL
originalUrl = data['body']['originalSrc']
# 获取帧信息
frames = data['body']['frames']
delays = [frame['delay'] for frame in frames]
# 发送GET请求获取原图ZIP文件
r = requests.get(originalUrl, headers=headers, verify=False)
zip_content = io.BytesIO(r.content) # 将响应内容加载到内存中的字节流,加快处理速度。
# 在内存中解压ZIP文件
with zipfile.ZipFile(zip_content, 'r') as zip_ref:
# 获取ZIP文件中的所有图片文件
image_files = [f for f in zip_ref.namelist() if f.endswith(('.png', '.jpg', '.jpeg'))]
image_files.sort()
# 读取图片并合成GIF
images = []
for image_file in image_files:
with zip_ref.open(image_file) as image_file_obj:
image = Image.open(image_file_obj)
image.load()
images.append(image)
# 合成GIF
if images:
images[0].save(
"download.gif",
save_all=True, # 保存所有帧。
append_images=images[1:], # 添加后续帧。
duration=delays, # 帧延迟时间(毫秒)
loop=0 # 循环次数,0表示无限循环
)
print("GIF文件已成功生成:download.gif")
else:
print("没有找到图片文件")后续
我也想试着通过做成浏览器插件来解决登录的问题,结果发现做到最后一步,还是受阻了😥🥲
经过一系列验证,我发现cookie里面真正有用的部分就是PHPSESSID那段,可以在开发者工具中存放cookie的应用程序查看,

可见因为被标记成HttpOnly,所以我无法通过js脚本获取,我以为又要没办法了。一搜,油猴脚本能暂时解决:
var session = "";
(function() {
'use strict';
GM_cookie('list', {
domain: "pixiv.net",
name: "PHPSESSID"
}, function (result) {
for (let cookie of result){
session = "PHPSESSID=" + cookie.value;
}
});
})();把这段代码导入篡改猴测试版,可以绕过HttpOnly的限制,但这会有安全隐患。
希望以后能找到更好的方法吧。。。。。。